Sentieon 2026Q2 Update Datasheet
While traditional linear reference genomes introduce bias and variant-calling errors, pangenome approaches resolve these issues by utilizing graph-based population haplotypes. The recently launched Sentieon pangenome pipeline brings this advanced analysis on generic hardware with a highly efficient fastq-to-VCF workflow.
This quarter, we have significantly expanded the pipeline’s capabilities:
- Broader Reference Support: The pipeline now natively supports CHM13 as reference in addition to GRCh38. Performance on NIST truth v5.0 has also been improved. We will also support GRCh37 in the future.
- Improved Rare Variant Sensitivity: The updated pipeline utilizes population information generated directly from the full pangenome graph. This change enhances rare variant sensitivity while generalizing the pipeline for non-human pangenomes.
- Ultima Solaris 2.0 Optimization: In close collaboration with the Ultima Genomics team, we updated our models to fully support their newly released Solaris 2.0 chemistry, achieving industry-leading variant-calling accuracy.
- Runtime & Cost Efficiency: The pipeline processes a 30x WGS dataset from FASTQ to comprehensive variant calls (SNP/Indel/SV/CNV) in just 82 minutes. Running on a 64-thread AWS c8i.16xlarge instance, the on-demand compute cost is approx. $4.10.
Section 1: Elevating Germline SNP/Indel Accuracy Across Standard v4.2.1 Benchmarks
Sentieon DNAscope Pangenome brings down the WGS error count to just 5,605—representing a 3.8x reduction compared to the linear DNAscope pipeline, while outperforming DRAGEN v4.5.
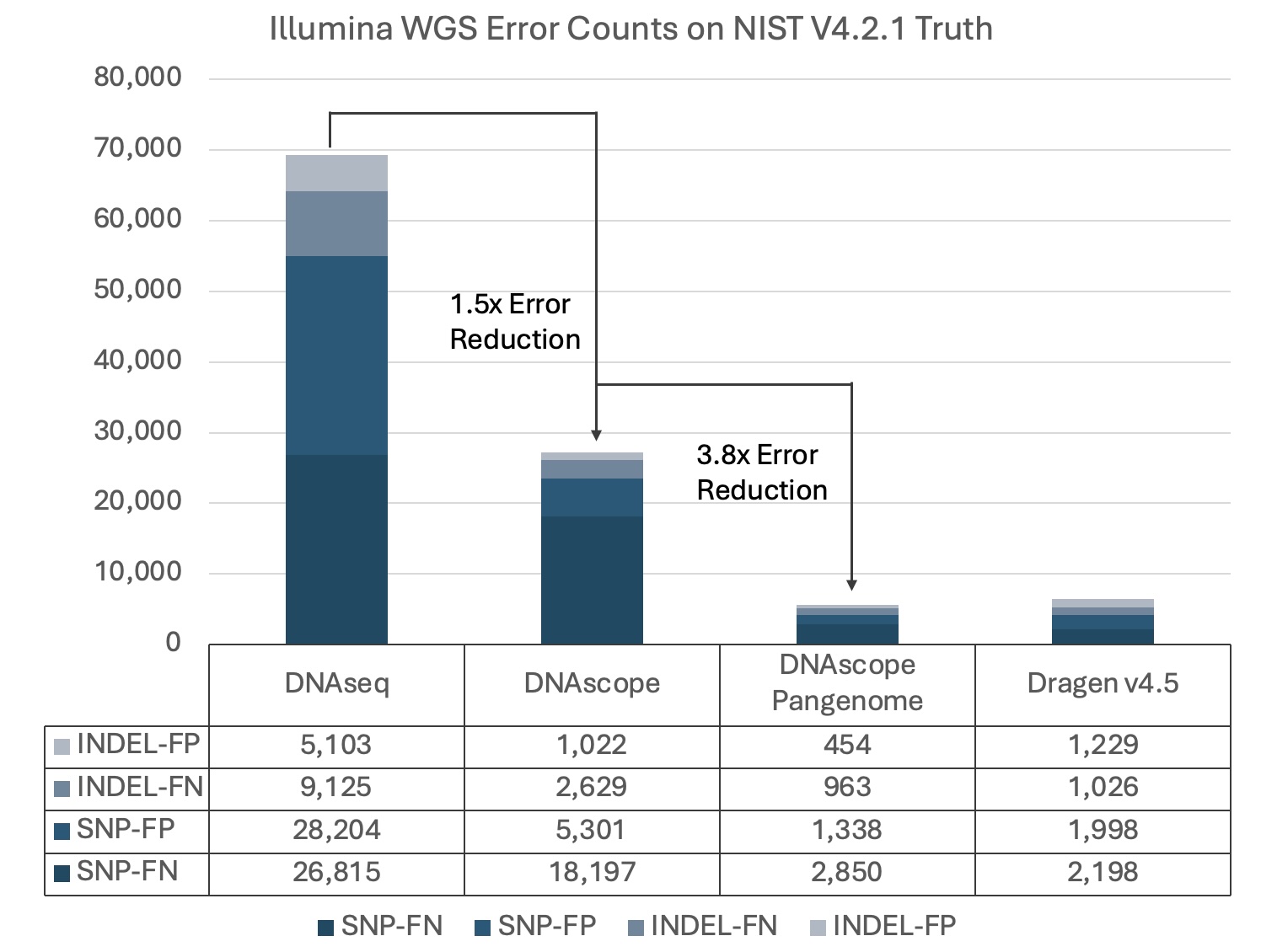
Figure 1. HG002 35x WGS (Illumina platform) error counts evaluated against NIST v4.2.1 truth data. DNAseq (Sentieon’s GATK reimplementation) and DNAscope both utilize the linear reference genome (Sentieon pipeline version 202503.03). DRAGEN performance figures are obtained from the v4.5 release update.
Section 2: Updated Model Training to Incorporate the GIAB v5.0 benchmark and the CHM13 Reference
The new model is trained using both the GAIB v4.2.1 and the newly released GIAB v5.0 (Q100-T2T) benchmarks. The v5.0 benchmark introduces additional training data on difficult repeat sequences that are uniquely included in its truth VCF, improving the performance of our pangenome model on these difficult regions. Additionally, integrating the CHM13 reference into our training has broadened the pipeline’s capabilities, proving that the workflow can seamlessly adapt to multiple reference genomes.
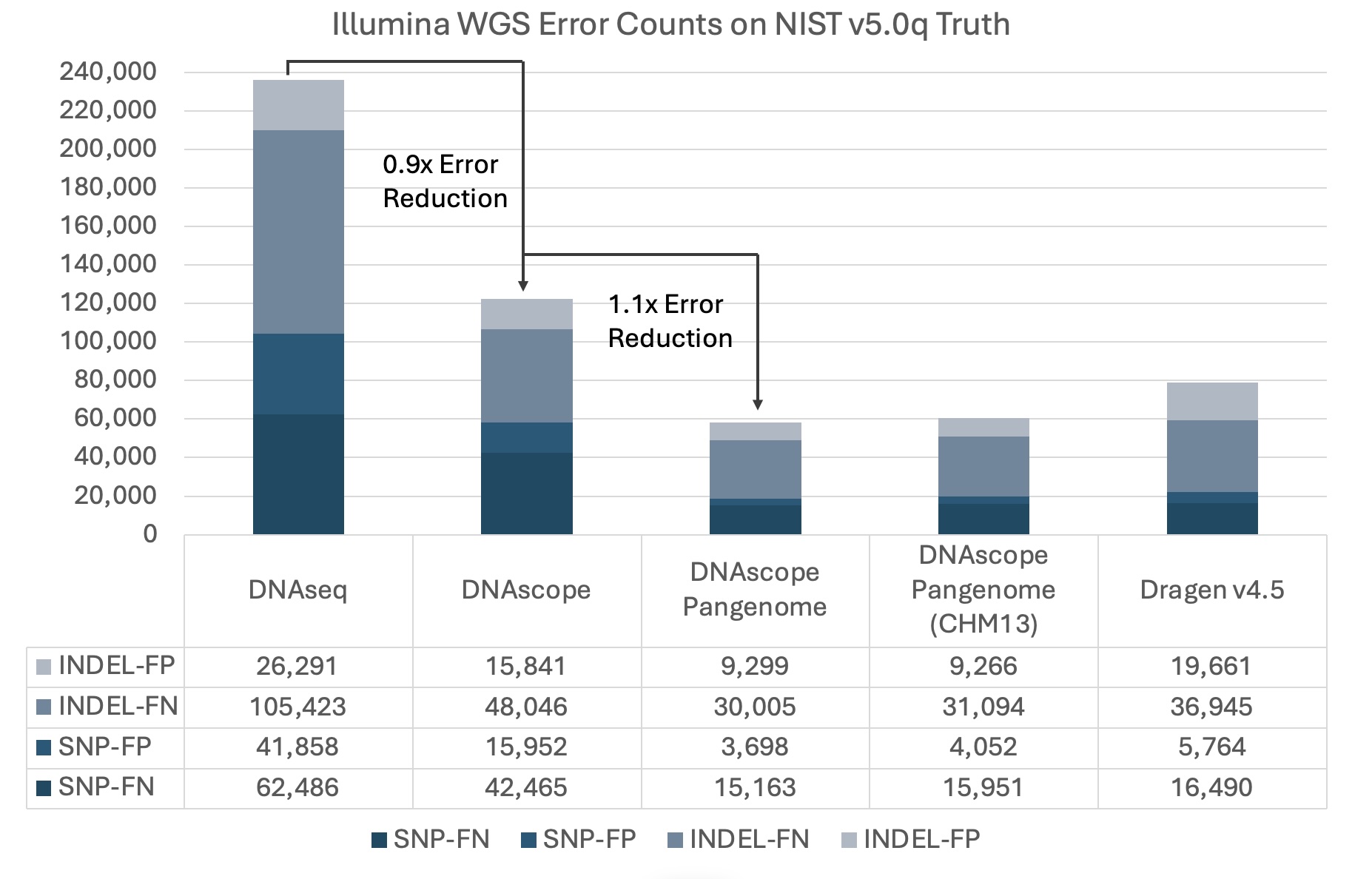
Figure 2. HG002 35x WGS (Illumina platform) error counts evaluated against NIST v5.0q benchmark with GRCh38 and CHM13 references. DNAseq (Sentieon’s GATK reimplementation) and DNAscope both utilize the linear reference genome (Sentieon pipeline version 202503.03). DRAGEN performance figures are obtained from the v4.5 release update.
Section 3: Maximizing Detection Sensitivity for Rare Variants
The DNAscope Pangenome pipeline, leveraging the HPRC pangenome graph, maintains high sensitivity for rare variants that are absent from the pangenome. We benchmarked the recall of rare variants (defined as sites excluded from the HPRC graph but cataloged in either dbSNP or gnomAD) across DNAscope Pangenome, DNAseq, and linear DNAscope using the v4.2.1 benchmark (HG003). The results confirm that DNAscope Pangenome delivers high recall across all variant sites; even those not included in the pangenome graph.
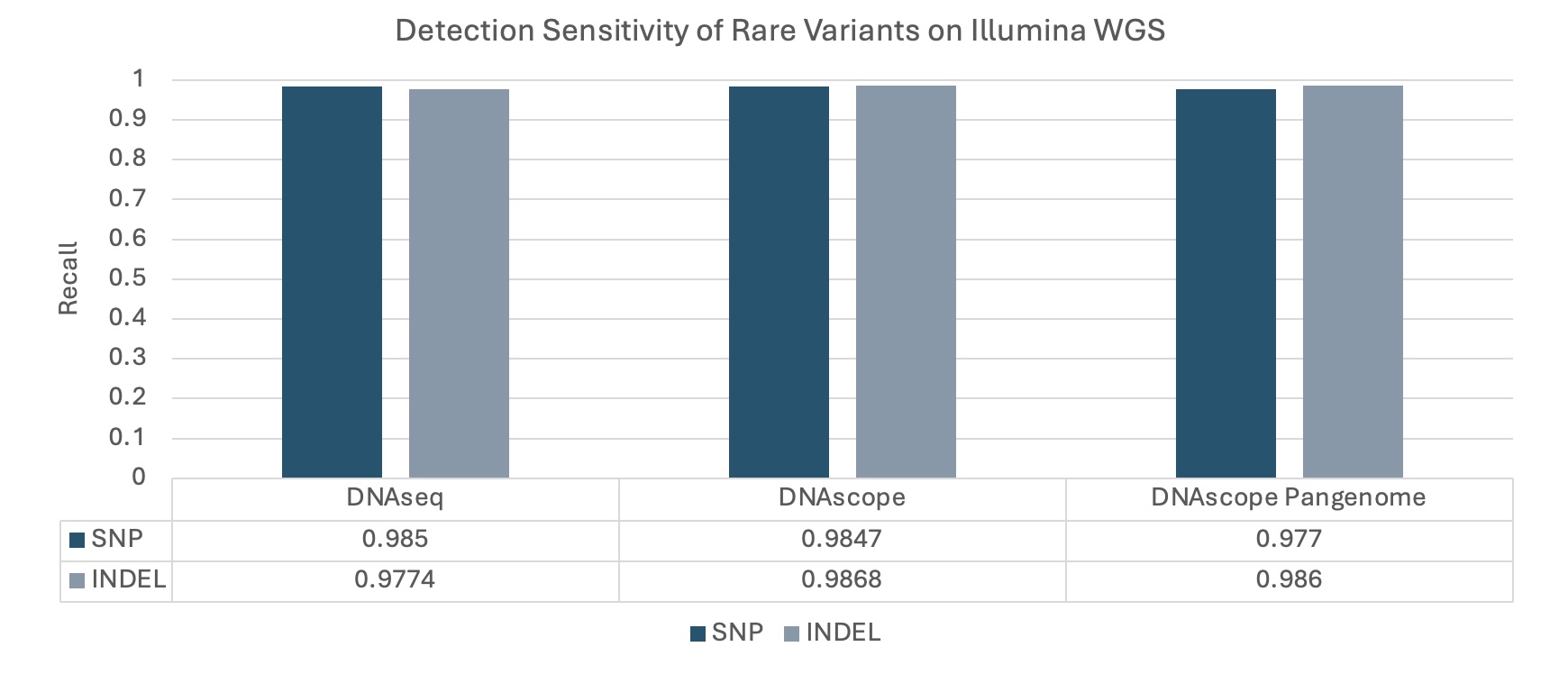
Figure 3. Detection Sensitivity of Rare Variants on 35x Illumina WGS (HG003). Recall is measured using GIAB v4.2.1 variant sites that are absent from the HPRCv2 pangenome and present in either the GnomAD or dbSNP.
Section 4: Delivering Industry-Leading Accuracy for Ultima Genomics WGS Analysis
The Sentieon pipeline supports most mainstream short- and long-read sequencing platforms. Our updated Ultima pipeline, retrained specifically for the Solaris 2.0 chemistry, outperformed DeepVariant’s accuracy on the same dataset released at AGBT 2026, establishing what is currently considered the industry-leading benchmark.
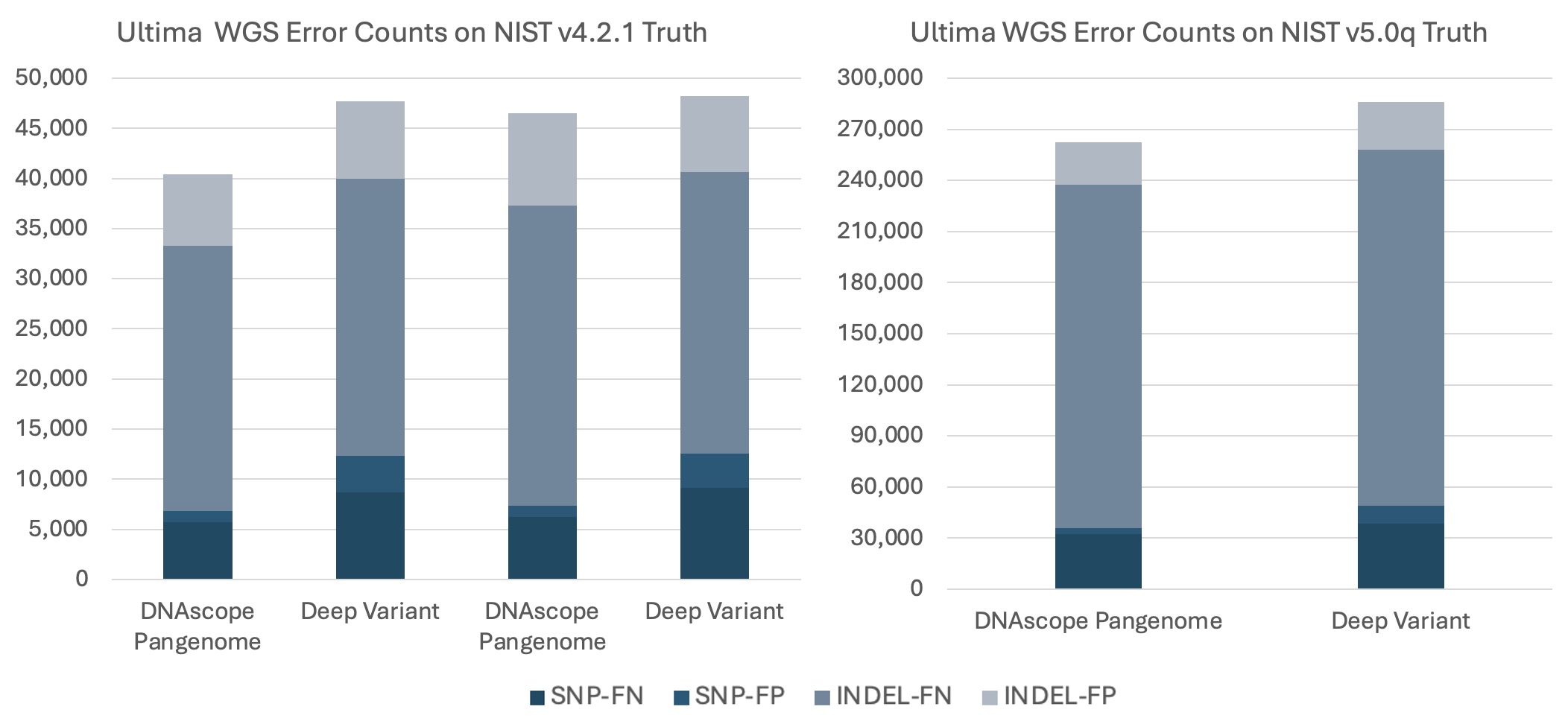
Figure 4. HG002 WGS error counts from the Ultima 2026 AGBT reference dataset using the GIAB v4.2.1 and v5.0q benchmarks. Sentieon pipelines utilize version 202503.03; DeepVariant accuracy was derived directly from the released 2026 AGBT VCF files.
Section 5: Comprehensive Structural and Copy Number Variant (SV/CNV) Detection
In addition to small variants, the DNAscope Pangenome pipeline excels at detecting structural variants (SVs) and copy number variants (CNVs). Benefiting from improved read alignment around breakpoints, the recall of SVs and small-sized CNVs shows a dramatic increase compared to traditional linear genome analysis.
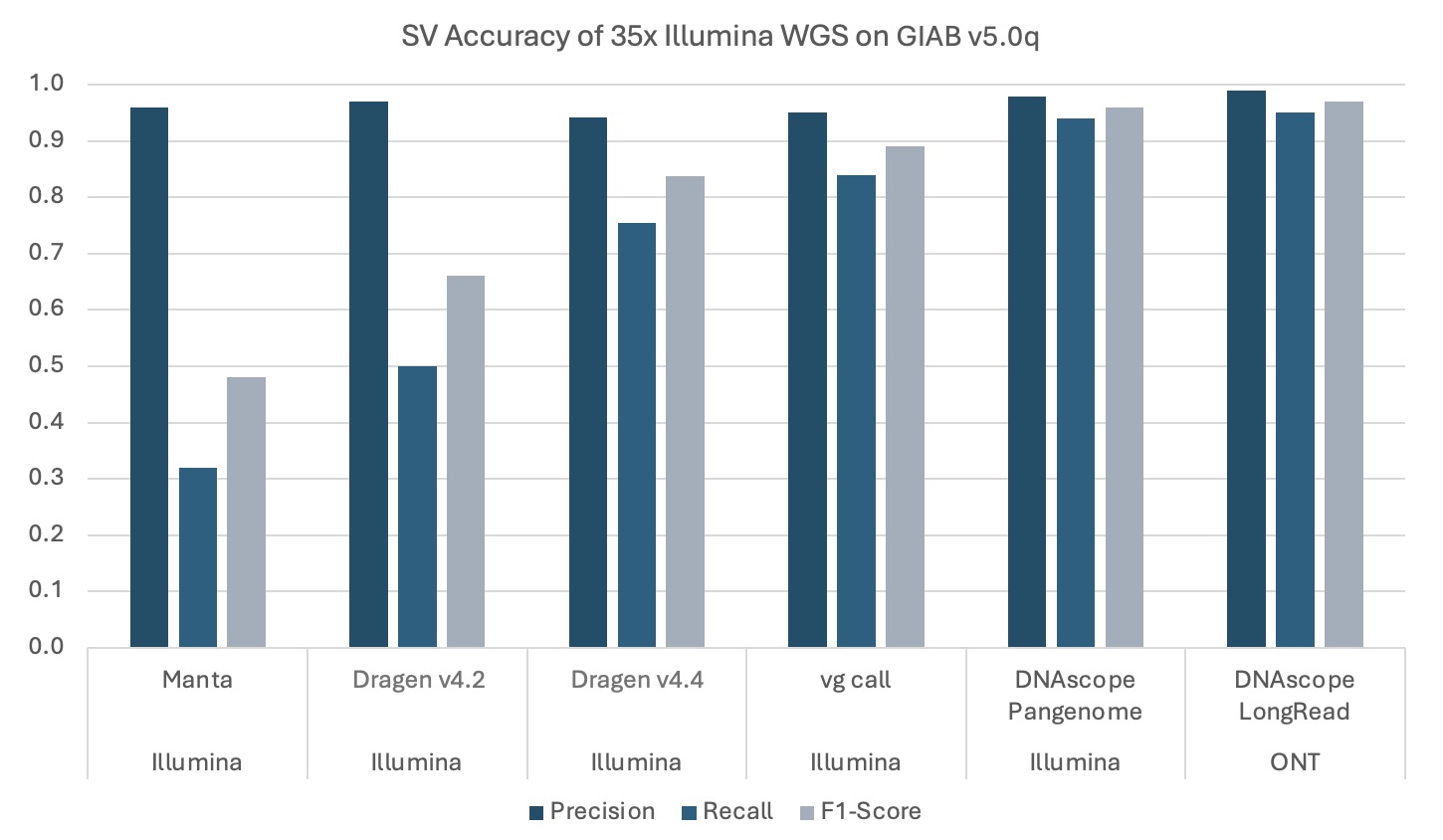
Figure 5. Comparative accuracy of benchmarked pipelines across NIST v5.0q. DNAscope Pangenome and DNAscope LongRead achieved the highest F1-scores, driven mostly by their higher recall in these challenging benchmarks. Long-read accuracies (ONT) are included for reference.
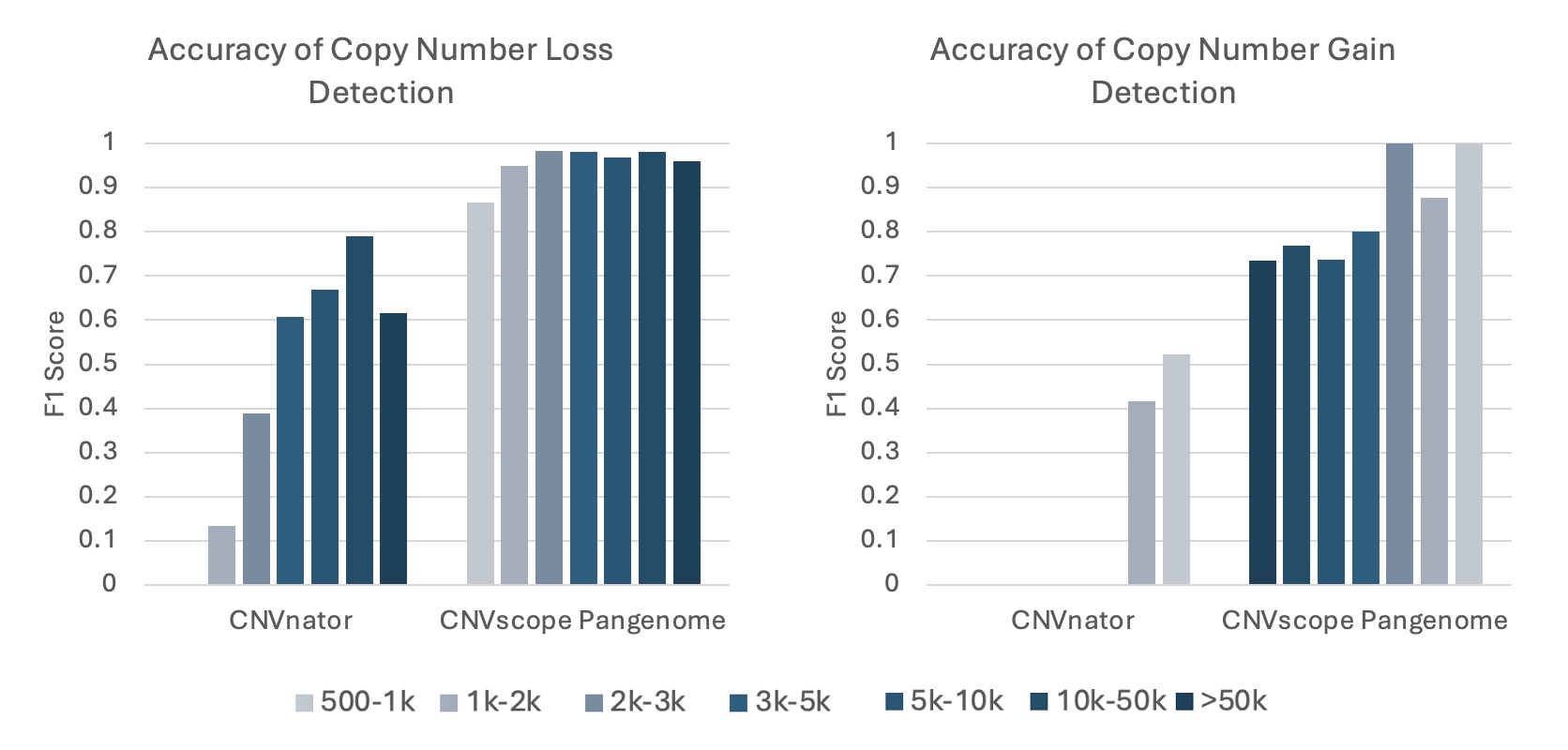
Figure 6. Comparative accuracy of benchmarked pipelines across the whole-genome CNV benchmark. CNVscope Pangenome significantly outperforms CNVnator, particularly for small events. The CNVscope Pangenome accuracy improvement is largest for copy number gains and smaller events, effectively pushing the reliable detection limit down to 500bp.